I am sure if you are reading this blog post, you have used Java collections a lot, and of course, you must have used Java Sets. The most common scenario, or rather the default reflex, is to go for a Set ( HashSet) whenever you want uniqueness.
Most often, developers ask just one question before choosing a Set as the main storage for their data: Does the data need to be unique?
If the answer is yes, they default to a Set.
However, in most cases, this data ends up being converted back to a List. You see this quite often in code: List dataList = new ArrayList<>(dataSet);
There are many reasons for this. Maybe you want to provide the data as a response in a JSON API and need order, or you are batching or paging and need specific items say 50 to 100. Or perhaps there is a method you defined, or even an external API, that accepts a List instead of a Collection.
In general, the issue is this: you write to a Set only a few times, or maybe just once, simply because you wanted uniqueness. But most often, the data is accessed in a way that requires a List. That is your read requirement. The application’s hot path almost always requires a List, yet you chose the data structure based on the write requirement (uniqueness), which rarely happens.
In the next section, we demonstrate the actual cost of this pattern by benchmarking three different scenarios.
The Benchmark: Read-Heavy Access
In this section, we compare three approaches to handling a cache of 10,000 unique items:
A standard List: We store the data in an ArrayList from the start and simply process it directly. This represents the baseline for performance where we satisfy our read requirements without any structural overhead.
A HashSet: Here we are forced to convert the set to a List on every read because we need in-order processing. This is the “Shuffle” scenario where we pay a massive allocation tax just to regain the list-like access we need.
LinkedHashSet: The data was stored initially respecting both uniqueness and insertion order. While we can iterate this directly without a conversion, we will see how the internal linked structure impacts the hardware’s ability to process data efficiently.
Here is the code for the benchmark:
@State(Scope.Benchmark)
@BenchmarkMode(Mode.Throughput)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@Warmup(iterations = 3, time = 1)
@Measurement(iterations = 10, time = 1)
@Fork(3)
public class ReadHeavyBench {
@Param({"10000"})
private int size;
private List<Data> arrayList;
private HashSet<Data> hashSet;
private LinkedHashSet<Data> linkedSet;
@Setup
public void setup() {
arrayList = new ArrayList<>(size);
hashSet = new HashSet<>(size);
linkedSet = new LinkedHashSet<>(size);
for (int i = 0; i < size; i++) {
Data d = new Data("ID-" + i, i * 1.5);
arrayList.add(d);
hashSet.add(d);
linkedSet.add(d);
}
}
@Benchmark
public double process_ArrayList() {
return calculate(arrayList);
}
@Benchmark
public double process_HashSet() {
return calculate(new ArrayList<>(hashSet));
}
@Benchmark
public double process_LinkedHashSet() {
return calculate(linkedSet);
}
private static double calculate(Iterable<Data> items) {
double result = 0;
for (Data d : items) {
result += Math.sqrt(d.value * d.id.hashCode());
}
return result;
}
static class Data {
String id;
double value;
Data(String id, double value) { this.id = id; this.value = value; }
}
}Build the application with mvn clean install and run using java -jar target/*.jar ReadHeavyBench -prof gc.
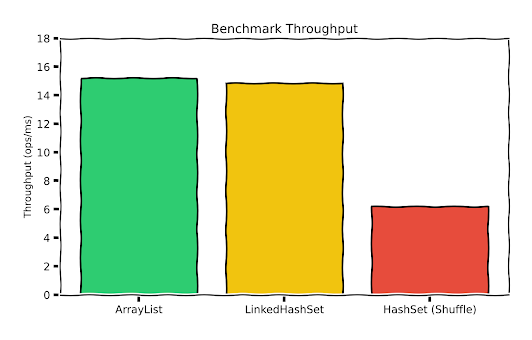
The Results
The results are self-explanatory and show the cost of choosing the wrong data structure, especially for a hot path. Here, the Set performs over 2x worse than the List in throughput and creates a massive memory overhead that the List completely avoids.
| Method Name | Throughput (Ops/sec) | Memory Allocated (Per Op) | Total Allocation (Per Sec) | GC Count (The Stops) |
|---|---|---|---|---|
| process_ArrayList | 15203 | 0.4 B | 0.007 MB/s | ≈0 |
| process_LinkedHashSet | 14855 | 30 B | 0.46 MB/s | ≈0 |
| process_HashSet | 6171 | 76 KB | 470.93 MB/s | 103 |

Conclusion
Using a Set to enforce uniqueness is a great tool, but it should not be the primary driver for your data structure choice. You must consider where the hot path is. Sets are efficient for frequent lookups and membership tests, but if you are mostly processing data in order, you probably need a List.
If you need to ensure uniqueness on a List, you can use Stream.distinct() during the write. If both uniqueness and insertion order are essential, a LinkedHashSet can serve as a compromise.
Always remember that every method call and structural conversion comes with a cost. Be mindful of where and when these overheads happen. Don’t let a one-time write requirement sabotage the long-term performance of your application’s hot path.

 Actually Matters")