There are times we write code and unintentionally some sort of patterns emerge.
Most times, we are not trying to “design a pattern.” We are just trying to make a feature work. And yes, sometimes we do have a clear picture of the problem we are trying to solve, just not a clear picture of the problem that comes afterwards.
Think of processing incoming ordered events. By ordered, I mean events must be processed in the order they arrive. But for each event, you also have different tasks to perform on it, some of which can run in parallel, while others must wait for certain steps to finish before they can proceed. So, you now have an issue of coordinating the flow correctly.
A typical way to do this is to fan out the event into different workers or handlers, let each one do its part, and then have some coordinating logic decide what can happen next. For example, one part may write to storage, another may validate or update state, another may record metrics, and another may send a response only after some of the earlier steps finish.
This works, and it is usually simple at first. But in doing this, we often end up creating a coordination layer without realizing it. We start adding checks, flags, maps, counters, and “only proceed if…” logic just to control order and dependencies across steps. So the code is not only doing business work, it is also coordinating when stages are allowed to move forward. The problem is that this coordination becomes scattered across the code, and the rule for what can move next is not very clear.
In this blog post, we will see how sequence barriers help with exactly that problem by giving you an explicit rule for when a stage is actually allowed to proceed. That small shift makes the coordination logic clearer, easier to reason about, and much harder to break as the flow grows.
The problem we are solving: Message delivery example
To understand this, let us use a real example.
Consider a message pipeline in a chat system, where you receive message events and each message must be delivered to a specific chat room. Let us represent a message event like this: Message(room=R, seq=N).
For each message, your system may need to do several things before delivery. It may need to persist it (store it), moderate it (for example, check for curse words or blocked content), replicate it (send or copy it to another node/service/backup instance for reliability), and then deliver it to clients in that room.
Clearly, some of these steps can run in parallel. But delivery may depend on some earlier steps finishing first, for example the message must be persisted and moderated before it is allowed to be delivered.
There is also an ordering rule. Messages in the same room must be delivered in the order they were received. So if Message(R, 101) arrives before Message(R, 102), then Deliver(R, 101) must happen before Deliver(R, 102).
A Typical First Version
A natural first version of this message pipeline is to split the work into separate parts when a message arrives.
So when Message(R, N) comes in, one part handles persistence, another handles moderation, another handles replication, another handles metrics, and then some coordinating logic decides when delivery is allowed.
This looks quite clean and reasonable because each step has its own job.

In fact, this is usually a good first version because it is easy to build and easy to extend at the beginning.
At first, this design looks fine because each async task reports when it is done, and the system reacts. But it is important to note that a “done” signal from any task does not automatically mean the next stage is allowed to move forward. In our chat example, if moderation finishes for Message(R,102), that still does not answer two important questions: has Message(R,102) also been persisted, and is delivery even allowed to move to 102 yet?
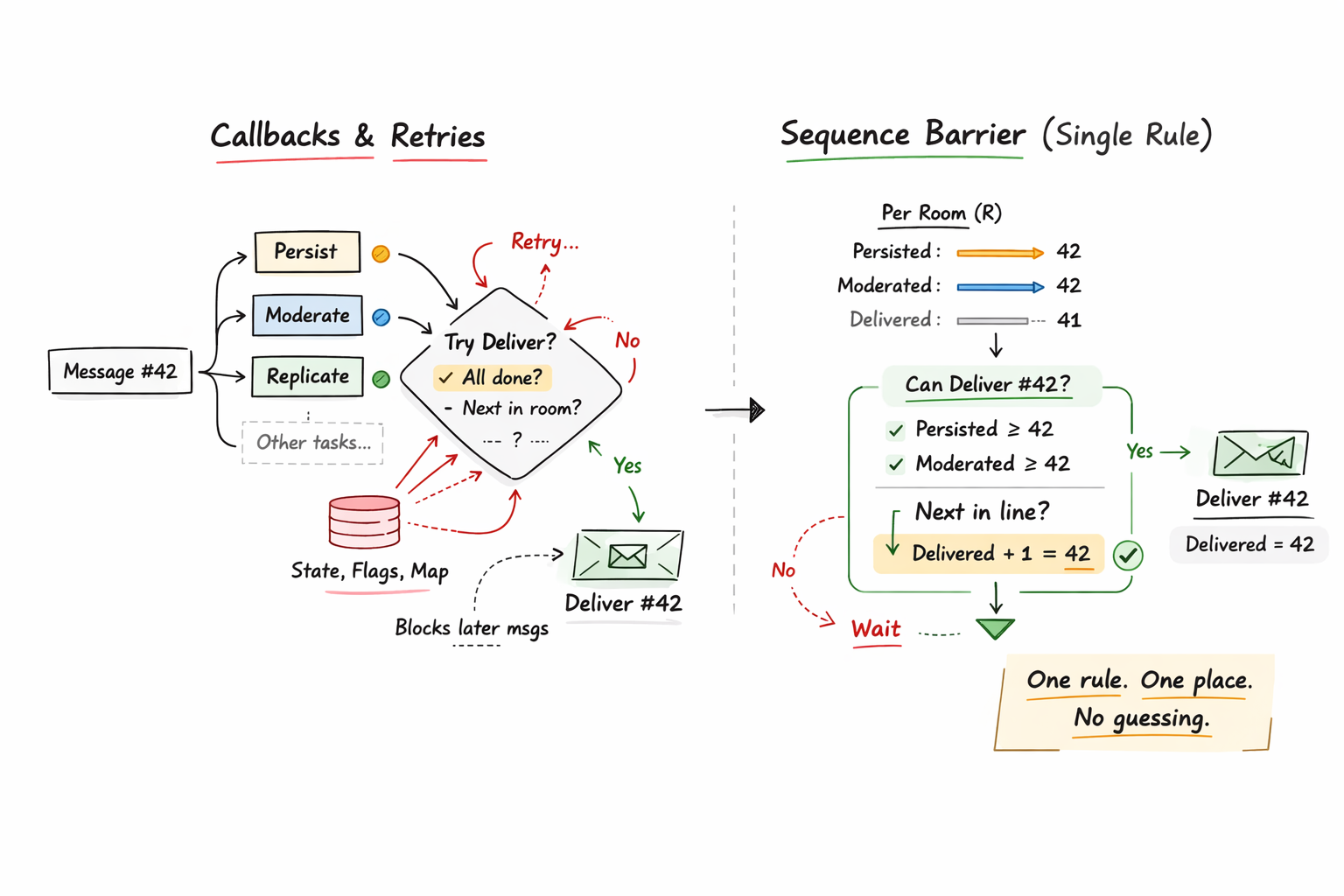
There are really two checks happening here. One is a within-message dependency check. For example, delivery waits for persistence and moderation of the same message. The other is an across-message order check. For example, Message(R,102) may already be ready, but delivery may still have to wait for Message(R,101) first. Because of this, the coordination logic may get more and more complex. In real systems, this can become very messy, and we are forced to introduce things like flags, maps, callbacks, and retry checks just to control what can move next.
A sequence barrier helps fix this by replacing those scattered checks with one clear stage-advancement rule. Instead of building complex logic from many “done” signals, the barrier checks whether the required sequence conditions are satisfied before allowing the next step to proceed.
Sequence Barrier (What It Is, and Why It Helps)
A sequence barrier is simply a rule that controls when a stage is allowed to move forward in an ordered pipeline.
In our chat example, delivery does not ask, “what tasks finished recently?” Delivery asks one specific question: “Can I deliver Message(R, N) now?”
So instead of building that decision from scattered “done” signals, callbacks, flags, and retry checks, we define it as one explicit stage-advancement rule.

In the first version, the delivery rule is spread across many small pieces of code. One part says the message was moderated, another says it was persisted, another checks whether an earlier message in the same room is still blocking delivery, and another retries later, so the system stays correct only if all those separate checks work together. A sequence barrier is better because it puts that same rule in one place at the delivery stage as a fixed gate for availability. Instead of guessing from scattered “done” signals and retries, delivery checks one clear rule before moving forward: are this message’s required steps finished, and is it the next message allowed to be delivered in this room? In other words, delivery stops being driven by whichever callback fired most recently and starts being driven by one explicit gate that decides whether the next message in line is actually available to move forward.
Pseudocode for Both Designs
Async completion glue style
In this version, the system reacts to task completions and keeps trying delivery as different parts finish.
onMessage(R, N, msg):
submit persist(R, N, msg)
submit moderate(R, N, msg)
submit replicate(R, N, msg)
submit metrics(R, N, msg)
onPersistDone(R, N):
state[R,N].persistDone = true
tryDeliver(R, N)
onModerateDone(R, N):
state[R,N].moderateDone = true
tryDeliver(R, N)
tryDeliver(R, N):
if state[R,N].persistDone
and state[R,N].moderateDone
and N == nextExpected[R]
and not state[R,N].delivered:
deliver(R, N)
state[R,N].delivered = true
nextExpected[R] = N + 1
flushReadyButBlocked(R)
Sequence barrier style
In this version, task completions still update progress, but delivery moves only by one explicit stage-advancement rule.
For each room R:
seqP[R] = highest persisted sequence
seqM[R] = highest moderated sequence
seqD[R] = highest delivered sequence
deliverBarrierOpen(R, N):
return seqP[R] >= N
and seqM[R] >= N
and N == seqD[R] + 1
tryAdvanceDelivery(R):
N = seqD[R] + 1
if deliverBarrierOpen(R, N):
deliver(R, N)
seqD[R] = N
tryAdvanceDelivery(R)
Where you usually see this (ring buffer / Disruptor)
In the LMAX Disruptor, sequence barriers are used with a ring buffer and sequence numbers. Producers publish events into the ring buffer, and consumers move through the stream by sequence number. A consumer does not move to the next sequence until its barrier conditions are satisfied.
So, in practice, sequence barriers are commonly discussed together with the Disruptor and its ring buffer. But the idea itself is more general:
A stage should move forward based on an explicit advancement rule, not just because some task finished.
Conclusion
In async pipelines, the problem is often not the tasks themselves, but the hidden coordination logic we build around them. If your delivery rule is spread across callbacks, flags, maps, and retries, that is a sign to stop and make the stage-advancement rule explicit.
Sequence barriers are useful because they force that rule into one clear place: the stage only moves when it is actually allowed to move. The practical takeaway is simple: look at one hot flow in your codebase and ask, is this stage moving because the right rule is satisfied, or just because some task finished?